Afin de pouvoir proposer une page avec au moins 10 résultats suite à une recherche d’un internaute, un moteur doit au préalable découvrir d’une manière ou d’une autre des sites pertinents.
Découvrir des URL et extraire leur contenu afin de le rapatrier dans d’immenses bases de données est une étape cruciale pour un moteur de recherche.
Il s’agit du crawl.
Crawler le web consiste d’une part à retourner sur des pages que le moteur connait déjà afin de repérer des mises à jour mais aussi à chercher de nouvelles URL afin de proposer des résultats toujours plus pertinents et plus frais.
Plan du cours
Robot, bot et spider
Les référenceurs français utilisent aussi bien les termes « Robot », « bot » ou « spider » afin de désigner le programme informatique chargé de crawler les sites web. On parle également de « scraping » même si ce dernier à une connotation souvent plus négative.
Concrètement le programme se connecte à l’URL, récupère les entêtes HTTP et le contenu renvoyés par le serveur du site web puis le ramène sur les serveurs du moteur de recherche afin d’être analysé par d’autres programmes.
User Agent
Chaque moteur dispose de robots qui sont la plupart du temps facilement repérables et identifiables.
Par exemple, le robot de Google le plus connu s’appelle GoogleBot. Celui de Bing s’appelle BingBot, celui de Yahoo s’appelait SLURP.
Les référenceurs utilisent des programmes qui sont aussi des crawleurs afin de simuler l’action des robots des moteurs de recherche et récupérer puis traiter plus facilement un grand nombre de données. Ces crawlers ont aussi des noms.
Par exemple, celui de logiciels Screaming Frog s’appelle par défaut « Screaming Frog SEO Spider ».
Ce nom est en fait un « User Agent ».
Lorsqu’on se connecte à une URL et qu’on demande à un serveur de nous retourner les entêtes et le contenu, si vous êtes bien élevé vous allez donner au préalable votre nom, c’est à dire votre User agent.
Un navigateur comme Chrome ou Firefox fait exactement la même chose lorsqu’il souhaite afficher une page. Par exemple, il peut indiquer comme user agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0
Pas de panique, il ne donne pas votre véritable identité. Ici on remarque qu’il déclare la version du logiciel utilisé.
SLURP, BINGBOT ou GOOGLEBOT sont en fait des « jetons user agent », le véritable user agent est plus long. Par exemple pour Google il peut s’agir de :
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Google utilise un grand nombre d’autres user agents et peut même parfois chercher à se cacher pour diverses raisons.
Etant donné qu’il s’agit d’un élément purement déclaratif, il est possible d’indiquer n’importe quoi.
Les référenceurs ont tous des plugins qui permettent de changer à loisir le user agent de leurs navigateurs et il peut s’avérer très pratiques de changer le user agent d’un crawler.
La discrétion est parfois importante….
Découvertes des URL
Lorsqu’un moteur lance son crawler pour la toute première fois de son existence c’est à dire lorsque son index est encore vide, on peut imaginer que ses concepteurs se lance un l’assaut d’un domaine comme Wikipedia car c’est un très gros site de confiance qui contient beaucoup de liens vers d’autres sites web.
Que se passe-t-il concrètement ?
Le robot se connecte à la page d’accueil, avale tout le code HTML puis le ramène.
D’autres programmes vont découper et analyser le contenu ainsi rapatrié. L’un de ces programmes aura pour tâche d’identifier les URL présentes dans le code source HTML.
Ces URL seront stockées dans des bases de données spécifiques « à la queue leu leu ». Il s’agit en quelque sorte de la « TODO List » des robots.
Toutes les prochaines URL à crawler sont ici.
Comme vous l’avez déjà compris, le robot va trouver la prochaine URL à crawler via ces bases de données et répéter ainsi l’opération ad vitam aeternam 7 jours sur 7 24H sur 24.
Pour faire crawler une nouvelle URL, il faut donc essayer d’obtenir et de déployer des liens qui pointent vers celle-ci.
Fonctionnement d’un robot en image
Le schéma ci-dessous issu d’un brevet déposé par les fondateurs de Google vous montre 3 étapes importantes que nous venons d’expliquer.
- URL SERVER : Endroit où sont stockées toutes les URL en attente d’être crawlées
- CRAWLER : Le robot qui va se connecter aux URL
- STORE SERVEUR : Endroit où le robot archive le contenu collecté
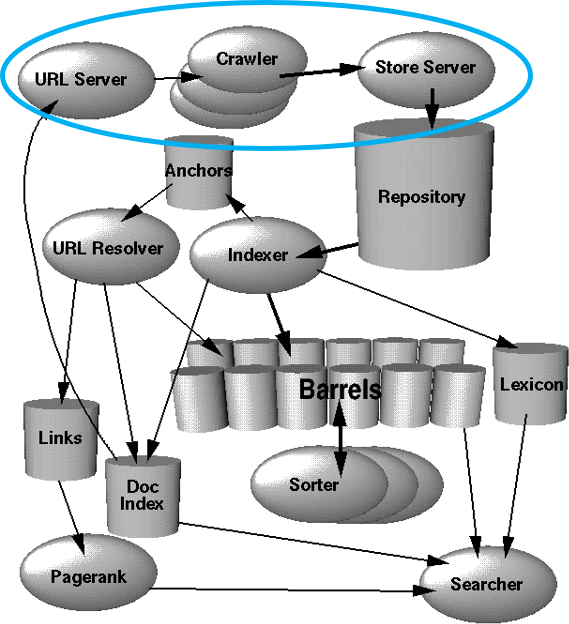
Sources de données
Les moteurs se sont rendu compte que procéder à des crawls en sautant ainsi de liens en liens ne suffisait pas.
Leur objectif est de découvrir les URL le plus rapidement possible afin d’être le plus pertinent notamment sur les requêtes dites « chaudes ».
A chaque fois qu’il faut aller sur Twitter pour chercher l’information la plus fraîche, il s’agit d’un échec pour les moteurs de recherche.
Google a rivalisé d’imagination afin d’être le plus rapide à indexer.
Ajouter des serveurs et donc de la puissance de calcul pour disposer d’un maximum de crawlers est une chose mais ils ont été encore plus ingénieux que cela.
Leur service Google Search Console permet de demander à GoogleBot un crawl quasi instantané de l’URL de son choix.
Les flux RSS et les sitemaps XML peuvent aussi aider.
On peut imaginer que de nombreux autres services servent de sniffeurs afin de découvrir de nouvelles URL à l’instar de Google Chrome. Ainsi recevoir beaucoup de trafic sur de nouvelles URL pourraient bien appâter GoogleBot.
Pendant une période, Google avait un partenariat avec Twitter afin de pouvoir crawler encore plus vite les tweets.
L’imagination permet d’envisager un grand nombre de méthodes pour découvrir de nouvelles URL.
Quoi de mieux par exemple que d’accéder aux DNS, c’est à dire aux bases de données qui stockent tous les noms de domaines associés aux IP des serveurs qui hébergent les sites afin d’obtenir la liste de tous les nouveaux noms de domaines déposés et lancer la cavalerie dessus ?
Notez bien que Google et Microsoft sont aussi propriétaires de câbles sous-marin reliant des pays et continents…
Robots.txt
Etant donné la voracité des bots, il a été jugé utile de pouvoir interdire explicitement certaines portions de son site aux crawleurs.
Cela se passe via un petit fichier au format texte qui est à placer à la racine de son site et qu’il faut nommer robots.txt
Attention à ne pas oublier le « s » final !
Dans ce fichier, il est donc possible de spécifier les URL autorisées au crawl (allow) et celles interdites (disallow).
Des règles de syntaxes et de priorités plus ou moins complexes permettent de cibler rapidement un grand nombre d’URL ou un type de fichier en une seule ligne.
Il est également possible d’appliquer certaines restrictions à certains bots et pas à d’autres via le fameux user agent que vous connaissez bien désormais.
Un robot est théoriquement respectueux des règles du fichier robots.txt et viendra donc le consulter fréquemment afin de savoir ce qu’il a le droit de faire.
Sachez toutefois que Google pourra très bien présenter dans ces pages de résultats une URL interdite au crawl s’il juge que cela est pertinent pour l’utilisateur. Et oui…
Dans tous les cas, ne vous attendez pas que les robots suivent les liens « chronologiquement » depuis la home page. Lorsqu’on observe le crawl il est parfois difficile de comprendre leur logique.
IP et Hôte
Une adresse IP (Internet Protocol) est un numéro qui identifie tout ce qui est connecté à Internet. Ce numéro peut être aussi bien fixe que variable.
Une IP fixe ne changera pas à chaque connexion.
Lorsque vous vous connectez à Internet vous avez une adresse IP.
Le serveur (ordinateur) qui héberge un site web possède une IP. Il est possible d’accéder à un site en tapant son IP mais vous conviendrez que retenir 208.80.154.224 à chaque fois que l’on souhaite aller sur Wikipedia n’est pas très pratique et qu’il est plus sympathique de taper un nom de domaine.
On chargera votre navigateur de demander à un serveur DNS qu’elle est l’adresse IP du nom de domaine à afficher pour faire la correspondance automatiquement.
Les robots qui sont des programmes exécutés depuis des ordinateurs qui se connectent à Internet ont donc aussi des IP.
Il est possible d’identifier les robots non seulement via un user agent mais aussi et surtout via une IP. Et il faut avouer qu’il est beaucoup plus difficile d’usurper une IP qu’un user agent.
L’IP peut vous donner accès à un nom d’hôte c’est à dire au nom de la machine qui fait fonctionner le robot.
Ainsi, si vous assemblez l’IP, le user agent et l’hôte, il devient beaucoup plus facile de découvrir l’identité et vérifier l’identité d’un crawler.

De nombreux robots de Google ont des IP qui commencent par 66.
Si vous voulez savoir si un robot appartient à Google ou non, il ne faut pas se fier uniquement au user agent trop facilement falsifiable. Il faut récupérer l’IP et faire une « résolution DNS » afin de connaitre le nom de la machine.
Il s’agit de la commande HOST reconnu par la plupart des ordinateurs ou d’utiliser un service en ligne.
Logs du serveur
Arrivé à cette étape de ce cours dédié au crawl et au SEO, vous allez nous dire que nous sommes bien gentils mais que vous ne savez pas comment récupérer l’adresse IP ou le user agent des robots qui crawlent votre site.
Pas de panique ! La majorité des serveurs archivent tout ce qu’ils font dans des « journaux ». Il s’agit de fichiers peu glamour qui listent ligne après ligne toutes les actions du serveur.
Dès que quelqu’un se connecte ou que le serveur exécute une action, il l’écrit dans le fichier de logs. C’est très pratique notamment pour comprendre et corriger des bugs, pour résoudre des problèmes de piratage mais aussi pour les référenceurs.
Pourquoi ? Car toutes les visites des robots sont inscrites dans ces fichiers.
Il y a longtemps, bien avant Google Analytics, on utilisait même les fichiers de logs comme sources de données pour connaitre le nombre et l’origine de ses visiteurs.
Pour la petite histoire, Google a racheté Urchin, un analyseur de logs célèbre avant de lancer Google Analytics.
Bref, voici l’exemple d’une trace laissée par un robot de Google dans des logs.
66.249.66.1 – – [13/Jan/2020:08:19:22] ''GET /robots.txt HTTP/1.1'' 200 0 ''-'' ''Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)''
On y trouve bien son IP (66.249.66.1), son user agent (Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html), la date et l’heure à laquelle il est passé « 13/Jan/2020:08:19:22 » et ce qu’il a fait sur votre site « GET /robots.txt » (demandé d’afficher le fichier robots.txt) et ce que votre serveur à répondu « 200 » c’est à dire « OK tout va bien je te donne ce que tu demandes ».
En analysant les logs, il est alors envisageable de connaître toutes les pages crawlées par les robots sur votre site.
Des techniques d’analyses SEO et d’optimisations existent à partir de ce type d’information mais cela n’est pas l’objet de ce cours dédié au crawl.
Vitesse, intensité et périodicité du crawl
Rappelez-vous, les moteurs doivent parcourir tous les web et proposer l’information la plus fraîche possible afin d’être pertinents.
Il va donc essayer d’engloutir énormément de pages le plus vite possible.
Toutefois, plusieurs problèmes se présentent :
- Crawler consomme de l’énergie et l’énergie coûte cher
- Il ne faut pas endommager votre site. Requêter trop rapidement un serveur peut le ralentir fortement et même le rendre inaccessible. On parle d’attaque par déni de service (DDOS)
- Il ne faut pas consacrer trop de temps à un site au détriment des autres
Il faut donc répartir intelligemment le crawl entre tous les sites web du monde.
Plusieurs tentatives ont existé afin d’aider ou d’optimiser le crawl des robots.
- Directive « Crawl-delay » dans le robots.txt
- Balise meta « revisit after »dans le code HTML
- Instructions changefreq et priority dans un fichier XML sitemap
- Etc
En ce qui concerne GoogleBot rien de tout cela fonctionne. Trop d’erreurs et trop d’abus ont été réalisés. Finalement les algorithmes de Google sont plus pertinents afin de déterminer quand ou où crawler.
Googlebot peut par exemple prendre en compte la popularité d’une page afin de l’estimer plus ou moins importantes à crawler. Il peut de lui même identifier les pages souvent mises à jour et celles laissées à l’abandon.
Le plus rigolo est quand GoogleBot repère une refonte de site. Il peut devenir extrêmement forasse durant une courte période. Ne paniquez pas c’est normal.
A contrario, si vous abandonnez un site peu populaire pendant 3 ans , il ne viendra presque plus le voir.
De la même manière, en fonction de la popularité de votre site et de la confiance que le moteur lui accorde, lui y consacrera plus ou moins de temps. On parle de « crawl budget ».
Voici une liste de ce qui peut influencer les robots
- Nombre de pages du site
- Popularité du site
- Popularité d’une URL
- Fréquence de mises à jour
- Nouveaux backlinks
- Nouveaux liens internes
- Trafic d’une URL
- Le profondeur de la page dans l’architecture du site
- Contenu dupliqué
Un crawler « intelligent » permet aux moteurs de limiter leurs dépenses en énergie, d’optimiser leur stockage et d’être plus pertinent en crawlant / rafraîchissant les bonnes ressources.
Crawl budget
Le crawl budget est le temps que décide de consacrer un moteur à crawler un site. Plus les pages de votre site seront rapides à crawler, plus le robot pourra en crawler en nombre important.
Pour la plupart des petits sites, la notion de « crawl budget » n’a aucun sens. En effet, les robots de Google étant tellement performants, ils ne feront qu’une bouchée de votre site.
En revanche pour les gros sites faisant plusieurs centaines de milliers de pages voir plusieurs millions alors le crawl budget peut être une notion importante en SEO.
En effet, faire crawler (que cela soit pour indexer ou mettre à jour) ses contenus pourrait ne pas être si automatique et ultra rapide que cela.
Il faudra trouver comment attirer GoogleBot au bon endroit et comment lui faire avaler un maximum de pages dans un minimum de temps.
Spider Trap
Un « spider trap » que l’on peut traduire en français par « piège à robot » est une sorte de gouffre, de boucle infinie qui va générer des URL à crawler de manière infinie.
Ainsi les robots n’arriveront jamais à terminer de crawler votre site car ils passeront leur temps à découvrir de nouvelles URL. Cela vous semble étrange ? Et pourtant il s’agit d’un problème courant.
Des systèmes de réservation ou de filtration sous forme de calendrier permettant de crawler chaque jour ou chaque mois jusqu’à l’année 2590 et bien plus.
Sur les sites E-ecommerce, les systèmes de tris sophistiqués et la navigation dites à facettes coupler à de la pagination peut aussi générer un nombre infini d’URL.
Des sites utilisant des identifiants de session dans les URL à chaque vite peuvent aussi généré énormément d’URL et en même temps dupliquer une quantité gigantesque de contenu.
Les référenceurs peuvent détecter facilement les spider trap avec l’expérience ou bien en exécutant eux même un crawleur et constater que le crawl ne se termine jamais.
Obfusquer des liens et Bot Herding
Afin d’éviter de faire crawler une URL, il est possible d’obfusquer des liens. Cela signifie rendre le lien incompréhensible pour le robot ainsi il ne pourra pas le suivre.
La technique dite de Bot Herding consiste à essayer de diriger / orienter les robots vers les pages les plus intéressantes pour le SEO.
Certaines référenceurs essayent de cacher des liens pointant vers la page panier ou des liens de partage vers les réseaux sociaux par exemple.
Entête HTTP 503
L’entête HTTP 503 signifie « Service unavailable » c’est à dire que l’URL à laquelle on tente d’accéder n’est pas disponible pour l’instant.
Il est possède d’envoyer cette entête HTTP à des robots afin qu’ils réduisent leur crawl. C’est très utile en période de forte affluence ou lorsqu’un site est en train de migrer.
Entête HTTP X-Robots-Tag
Il est possible d’envoyer des directives aux robots via l’entête HTTP X-Robots-Tag.
Par exemple, il est possible de dire aux robots de ne suivre aucun lien sur la page si vous voulez limiter le crawl vers ces pages ainsi que la popularité transmise.
<?php header("X-Robots-Tag:nofollow", true); ?>
Meta robots nofollow et rel=nofollow
Voici l’exemple d’une meta robot nofollow
<meta name="robots" content="nofollow" />
Et voici l’exemple d’un attribut rel=nofollow appliqué à un lien
<a href="https://www.cours-referencement.fr/" rel="nofollow">Cours référencement</a>
Cela permet de dire aux robots de ne pas crawler les liens découverts via ce lien (rel) ou cette page (meta) et aussi de ne pas transmettre de popularité.
Notez toutefois que les robots pourraient parfaitement crawler les pages liées malgré cette balise et cet attribut. Il peuvent trouver un autre lien sur une autre URL ou bien tout simplement ne pas respecter à lettre votre demande.
Crawl mobile vs Crawl Desktop
Auparavant, Googbot était activé avec un user agent Desktop. C’est à dire qu’il était détectable comme un utilisateur utilisant un ordinateur avec un écran classique.
Progressivement avec l’essor de l’utilisation du mobile partout dans le monde, Google a décidé d’utiliser un « crawler mobile ». C’est à dire que le user agent de GoogleBot est maintenant similaire à un utilisateur utilisant son téléphone pour consulter un site.
Qu’est-ce-que cela change ? Les développeurs utilisent des techniques d’intégration et de programmation parfois spécifiques et distincts entre les devices afin d’adapter au mieux l’affichage des sites.
Ainsi il pouvait y avoir des variations dans le code HTML d’une page entre sa version mobile et desktop. Désormais, sur la majorité des sites, Google est passé à l’index Mobile First.
La version mobile sera donc prioritaire par rapport à la version desktop. Pour savoir si cela concerne votre site, il est possible de réaliser une analyse de logs et de consulter le service Google Search Console.
Le Crawl avec exécution du Javascript
De plus en plus de sites utilisent des frameworks Javascript pour afficher du contenu alors même que très peu d’interactions avec les utilisateurs sont attendues.
Ce type de technologie génèrent d’immenses problèmes en SEO et il faut mieux absolument les éviter lorsque cela est possible.
Si les robots des moteurs de recherche doivent exécuter javascript pour accéder à du contenu important pour le SEO, le crawl de votre site va être terriblement impactés.
Le crawl par défaut de Google n’exécute par javascript. Cela est beaucoup trop couteux à l’échelle du web de faire effectuer javascript systématiquement.
En effet, Javascript est un langage qui s’exécute coté client et non coté serveur. C’est à dire que c’est à la machine de l’internaute de travailler et non pas au serveur du site.
Vous voyez l’impact pour les moteurs de recherche ?
Toutefois, des robots comme GoogleBot exécutent de plus en plus fréquement les scripts JS.
Cela arrive souvent via une « deuxième vague » de crawl. Qui dit deuxième vague dit qu’il faut déjà avoir eu une programme vague. Il s’agit donc de temps perdu pour obtenir de bons résultats en SEO.
Concrètement, oui, GoogleBot est capable d’exécuter du javascript (sauf si votre code est vraiment trop lent) . Il est possible de positionner un site qui utilise en framework JS.
De très gros sites fonctionnent ainsi. C’est juste que c’est plus compliqué, plus long et plus coûteux. Sur des thématiques concurrentielles, il est absolument déconseillé de faire effectuer le JS par les robots pour les éléments importants de votre site.
Il semble exister un web à 2 vitesses. Les gros sites bien vus par Google semblent bénéficier d’un traitement privilégier et recevoir plus volontiers les robots qui exécutent JS.
La solution pour optimiser le crawl des sites qui fonctionnent sous JS est le cloaking. C’est à dire de détecter qu’il s’agit d’un bot et de lui envoyer directement un snapshot HTML du code généré.
Ainsi les robots n’auront plus besoin de javascript pour crawler efficacement l’intégralité de votre site.
Crawl caching proxy
Google utilise un grand nombre de robots différents qui ont des rôles distincts. Afin d’économiser du temps de crawl et de l’énergie, des robots avec des user agents non identiques peuvent très bien partager certaines informations entre eux.
Une fois que le contenu d’une URL est crawlé puis rapatrié sur les serveurs de Google, les autres pourront se servir de ce cache s’il est assez frais plutôt que de revenir sur votre propre serveur.
Deep web
Le deep web représente les informations qui ne sont pas accessibles aux moteurs de recherche. Le deep web est bien plus vaste que le reste du web.
Pensez à la taille colossale des données auxquelles il n’est pas possible d’accéder via un moteur de recherche.
Globalement il s’agit de tout ce qui n’est pas référencé ou référencable :
- Contenu accessible sans aucun lien et dont les robots n’ont pas découvert l’URL
- Contenu protégé via un authentification (backoffice, intranet)
- Contenu de bases de données accessibles
- Contenu dans le format n’est pas compris par les robots
Synthèse
- Le crawl est la première étape du référencement
- Le crawl permet de découvrir des nouveaux contenus à indexer
- Le robot d’un moteur essaye de parcourir toutes les pages d’un site
- Un robot est identifiable via un user agent, une IP et un hôte
- Le robot laisse des traces dans un fichier de logs
- Un robot utilise les liens dans le code HTML pour trouver de nouvelles URL à crawler
- Les moteurs utilisent d’autres sources de données pour découvrir toujours plus d’URL
- Bot, spider, robot et crawleur signifie la même chose
- Il n’est pas possible de contrôler facilement le rythme des crawlers
- Pour faire crawler une URL, idéalement, il faut déployer des liens vers cette URL
- Le fichier robots.txt placé à la racine de chaque site permet de gérer le crawl